To extend the scope of coding queries to more realistic settings,
we propose ODEX, the first Open-Domain EXecution-based natural language (NL) to code generation dataset.
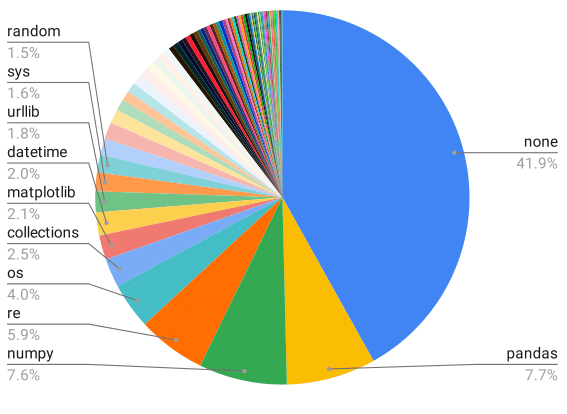
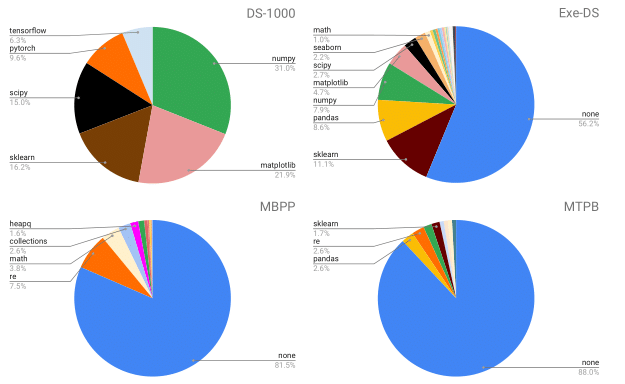
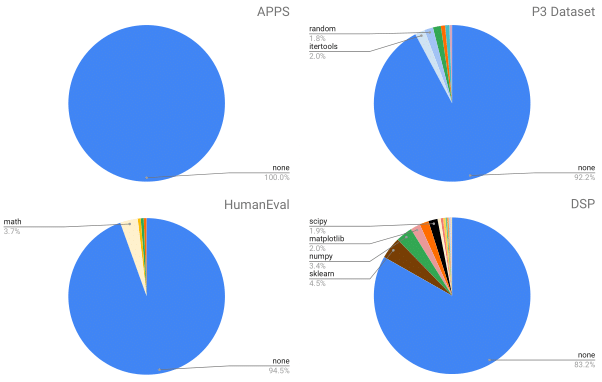
ODEX has 945 NL-Code pairs spanning 79 diverse libraries, along with 1,707 human-written test cases for execution.
Our NL-Code pairs are harvested from StackOverflow forums to encourage natural and practical coding queries.
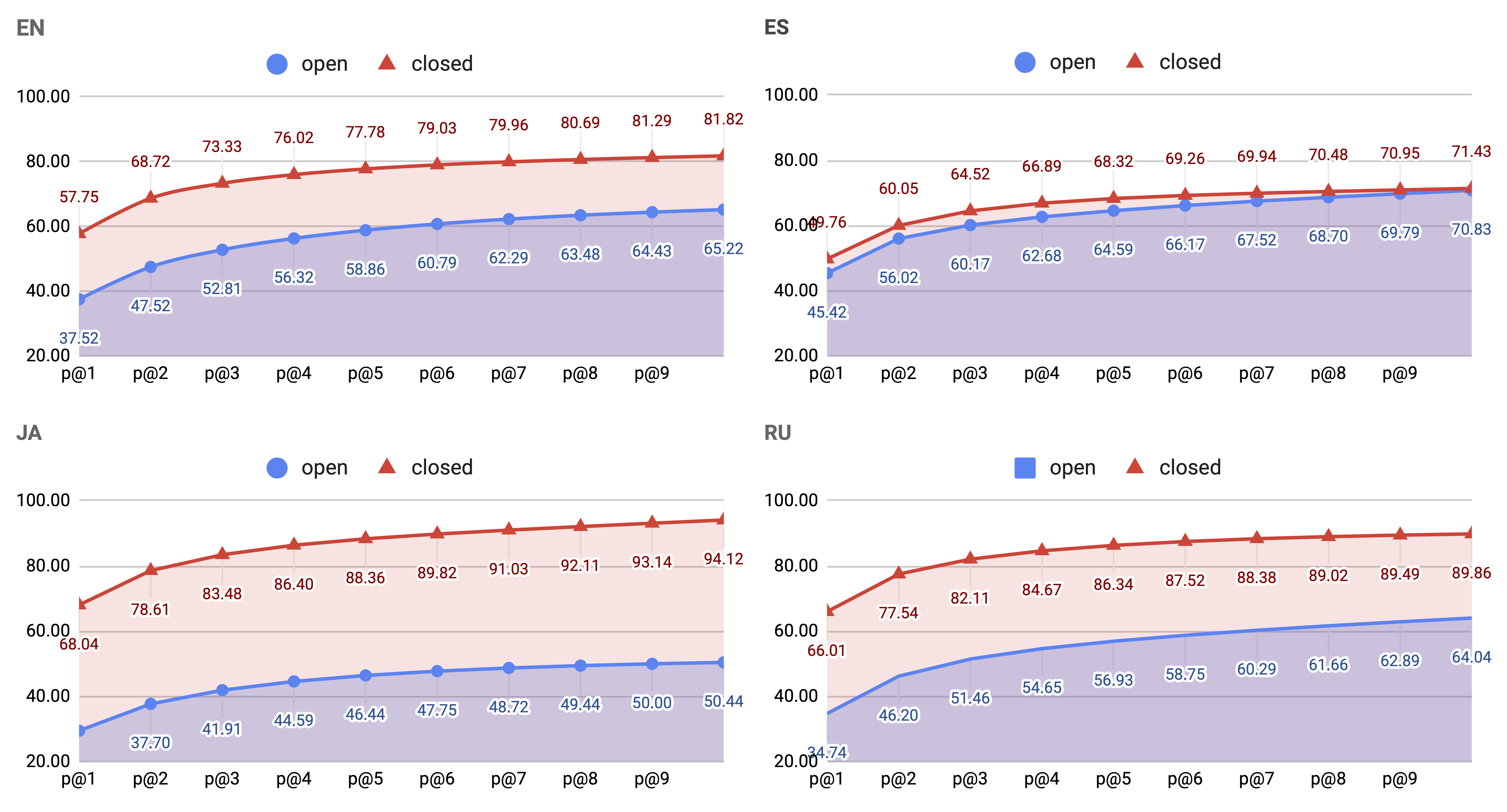
Moreover, ODEX supports four natural languages as intents, in English, español (Spanish), 日本語 (Japanese),
and Pусский (Russian).
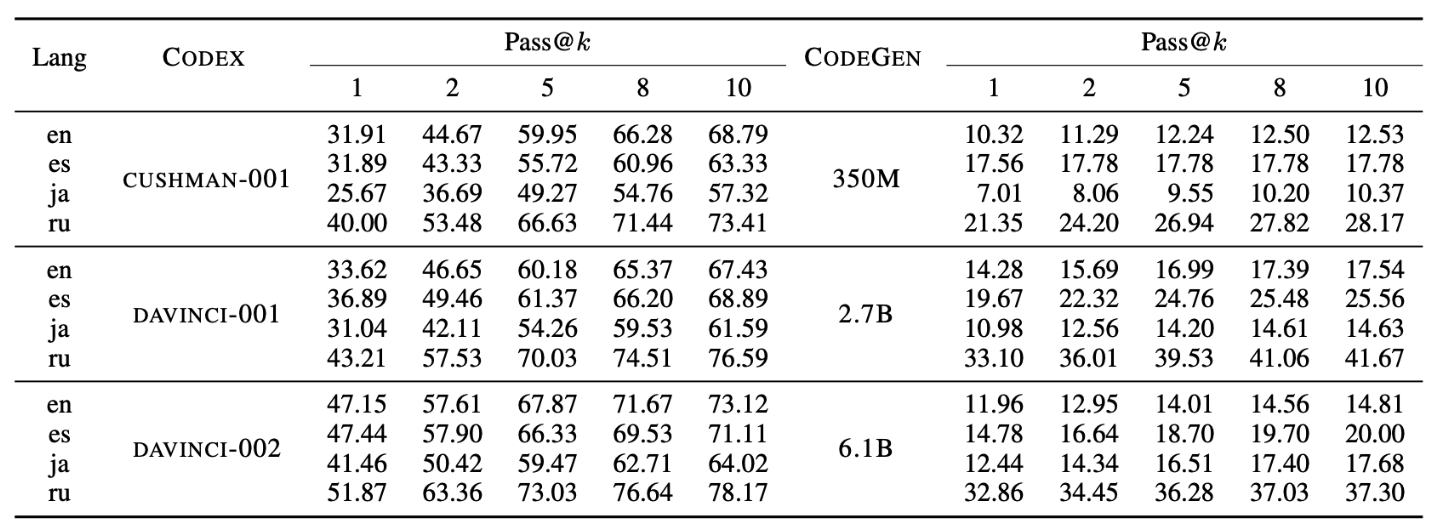
ODEX unveils intriguing behavioral differences between top-performing Code LMs: Codex performs better on open-domain queries,
yet CodeGen captures a better balance between open- and closed-domain.
ODEX corroborates the merits of execution-based evaluation over metrics without execution but also unveils their complementary effects.
Powerful models such as CodeGen-6B only achieve an 11.96 top-1 pass rate, suggesting plenty of headroom for improvement.